L'optimisation des moteurs de recherche a complètement changé en 2026.
Les anciennes méthodes reposaient sur la correspondance de mots. Les nouvelles méthodes reposent sur le raisonnement, la synthèse et la prédiction de ce que veulent les utilisateurs.
Les grands modèles linguistiques (LLM) et les systèmes de correspondance neuronale alimentent désormais la recherche.
L’écosystème s’est scindé en deux mondes parallèles :
- Résultats biologiques traditionnels – Les classiques « 10 liens bleus ».
- Optimisation du moteur génératif (GEO) – Les règles pour les aperçus de l’IA et les réponses générées par l’IA.
Plus de 60 % des recherches d’informations se terminent désormais sans un clic.
Les anciens facteurs de classement...densité des mots clés et le nombre brut de backlinks – ne domine plus.
Qu'est-ce qui gagne aujourd'hui ?
Autorité basée sur l’entité. Cohérence du signal multimodal. Commentaires implicites des utilisateurs.
Ce guide couvre tous les facteurs de classement confirmés, corrélés et observés pour 2026.
Nous avons synthétisé les données de plus de 200 signaux algorithmiques distincts.
Voici la taxonomie définitive de ce qui détermine réellement la visibilité mondiale des recherches.
Le changement de paradigme : optimisation des moteurs génératifs et aperçus de l'IA
Les aperçus de l'IA ont changé la façon dont les gens obtiennent du trafic.
Ils traitent plus de 2 milliards d’utilisateurs actifs mensuels. Ils apparaissent dans près de 48 % de toutes les recherches.
Ces résumés génératifs répondent aux questions directement sur la page de résultats. Les utilisateurs obtiennent ce qu'ils veulent avant de cliquer sur quoi que ce soit.
Les modèles d'IA sous-jacents comprennent :
- PaLM2 – Pour la génération de langage naturel
- Gémeaux – Pour une compréhension multimodale
- Une maman modifiée – Pour l’analyse de requêtes complexes
Ces modèles évaluent le contenu avec leurs propres critères de classement.
Ces critères sont parallèles à l’indice biologique traditionnel. Ils sont indépendants.
Voici la preuve :
Seules 38 % des pages citées dans AI Overviews se classent également parmi les dix premiers résultats traditionnels pour la même requête.
Pour gagner dans un monde génératif, vous avez besoin d’une méthode d’optimisation distincte.
Se concentrer sur:
- Extractibilité du contenu – L’IA peut-elle extraire facilement vos faits ?
- Autorité de l'entité – Le monde reconnaît-il votre marque en tant qu’expert ?
- Fréquence de citation – À quelle fréquence les modèles d’IA vous mentionnent-ils ?
Part des signaux d’entité de modèle et de marque
Dans un monde sans clic, les mesures de trafic traditionnelles n’offrent plus une visibilité totale.
L'industrie utilise désormais Part du modèle comme principal indicateur de performance.
Qu'est-ce que la part du modèle ?
Il mesure la fréquence à laquelle un modèle d'IA cite votre entité dans un domaine spécifique.
Considérez-le comme une part de marché, mais pour des réponses génératives.
Quels sont les facteurs les plus importants pour l’inclusion de l’IA ?
Validation des entités hors site et ubiquité de la marque. Ils se classent au-dessus des mesures traditionnelles sur site.
Corrélations des facteurs de visibilité du moteur génératif
| Facteur | Corrélation | Ce que cela signifie |
|---|---|---|
| Mentions Web de marque | 0.664 | Mentions de marque non liées sur les modèles linguistiques de train Web. Ils construisent une autorité sémantique. |
| Texte d'ancrage de marque | 0.527 | Les mentions liées à votre nom de marque renforcent l’identité de l’entité. Ils comptent plus que les ancres génériques. |
| Volume de recherche de marque | 0.392 | Un volume de recherche élevé de marque montre une demande externe. Les modèles d’IA voient cela comme un signal de confiance. |
| Évaluation du domaine | 0.326 | L’ancienne autorité de domaine est toujours utile, mais moins qu’avant. Les modèles préfèrent les mentions d’entités aux capitaux propres des liens. |
| Volume total de backlinks | 0.218 | Le nombre brut de backlinks a une faible corrélation avec les citations de l’IA. La qualité et le contexte comptent désormais davantage. |
| Nombre total de pages du site | 0.170 | La taille du domaine est le prédicteur le plus faible. L’IA privilégie une couverture approfondie d’un sujet, et non de nombreuses pages superficielles. |
Les données montrent une « falaise de visibilité ».
Les marques figurant dans le top 25 % des mentions Web mondiales reçoivent jusqu'à dix fois plus de citations IA que les marques du quartile inférieur.
Pourquoi ?
Les modèles de langage synthétisent les réponses basées sur un consensus mathématique et la prévalence des entités dans les données de formation.
De petits avantages en termes de notoriété de la marque créent des gains exponentiels en termes de visibilité de l'IA.
Comment capitaliser ?
Structurez votre contenu pour l'extraction :
- Des hiérarchies de titres claires
- Structures de paragraphe concises
- Gain d'informations ciblé qui facilite l'analyse machine
L'architecture de la qualité du contenu et E-E-A-T 2.0
La qualité du contenu reste l’élément le plus important dans le classement organique traditionnel.
Il représente environ 23 % de la hiérarchie de classement.
L'expertise thématique de niche suit à 13 %.
Mais la « qualité » a changé.
Il ne s’agit plus de densité de mots clés.
Cela signifie désormais profondeur sémantique, gain d'informations et cadre E‑E‑A‑T 2.0.
Les piliers de l’E‑E‑A‑T 2.0
Google a ajouté « Expérience » aux directives de l'évaluateur de qualité.
Ce changement cible directement le contenu IA purement synthétisé.
Les modèles génératifs manquent d’expérience vécue.
Les domaines utilisant de vrais auteurs humains bénéficient d’un net avantage.
Voici les quatre piliers :
1. Expérience
Votre contenu montre-t-il des rencontres vécues ?
Documente-t-il les processus réels ?
Inclut-il des preuves visuelles originales ?
Les résumés généraux anonymes sont dévalorisés.
Ce qui fonctionne : récits à la première personne, ensembles de données originaux, images personnalisées, études de cas détaillées.
Ceux-ci prouvent que vous avez réellement interagi avec le sujet.
2. Expertise
Mesuré par la profondeur sémantique.
Également mesuré par l'exactitude des relations entre entités et des groupes thématiques.
Le modèle en piliers fonctionne le mieux : une page centrale renvoyant à des sous-thèmes détaillés.
Cela montre que vous possédez l’intégralité du sujet.
3. Autorité
Ceci est accordé à l’extérieur et non réclamé.
Calculé grâce à des backlinks contextuels de haute qualité, des mentions de relations publiques numériques et une inclusion dans des listes d'experts.
4. Fiabilité
C'est la couche de base.
Déterminé par la sécurité technique, des informations commerciales précises, des signatures d'auteur transparentes avec des informations d'identification vérifiables et une expérience utilisateur stable.
Si votre domaine ne dispose pas de HTTPS ou de normes éditoriales claires, vous ne respectez pas le seuil de confiance.
Votre expertise et votre expérience perdent toute valeur algorithmique.
Facteurs sémantiques et structurels au niveau de la page
Au niveau granulaire, l'algorithme évalue chaque document HTML à l'aide de ces facteurs raffinés.
| Facteur | Comment ça marche en 2026 |
|---|---|
| Mot-clé dans la balise de titre | Cela reste un signal de pertinence primordial. Les mots-clés proches du début sont légèrement utiles. Le phrasé naturel surpasse la farce exacte. |
| Mot-clé dans la méta description | Pas un facteur de classement direct. Mais des descriptions convaincantes et riches en mots clés augmentent le CTR. Cela alimente les modèles de classement comportemental. |
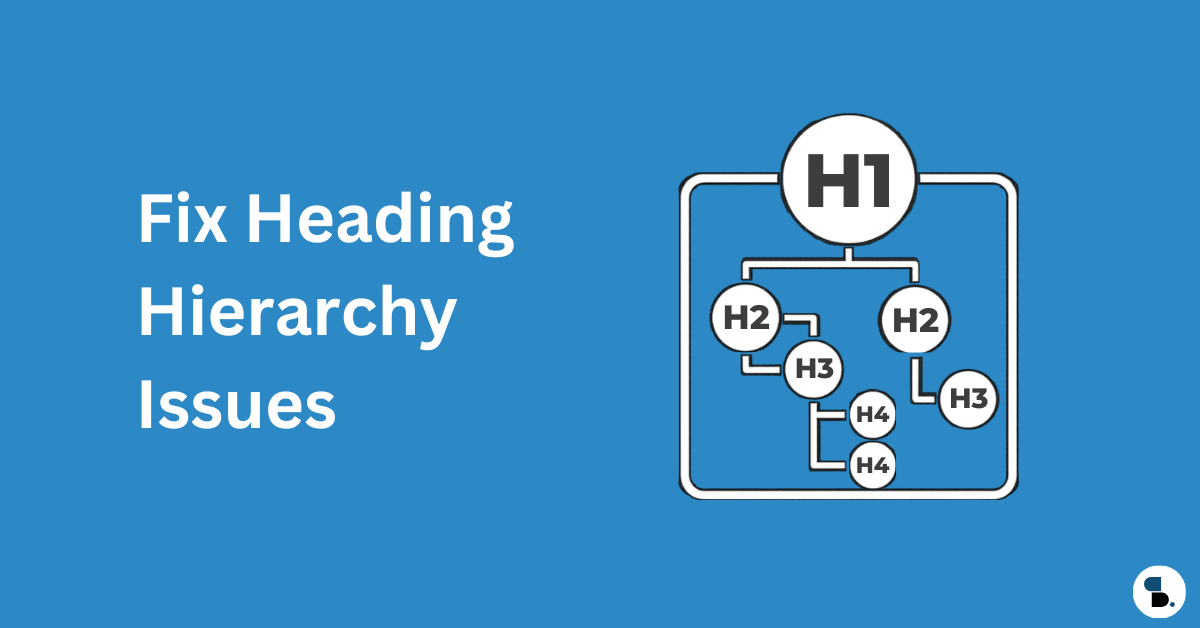
| Mot-clé dans la balise H1 | Le signal structurel définitif du sujet principal de votre page. Les H1 manquants ou en double nuisent à l’extraction d’entités. |
| Fréquence des mots clés / TF-IDF | Fréquence des termes – La fréquence inverse des documents calcule l’occurrence des termes par rapport au contenu normal. Une fréquence équilibrée montre la pertinence. Trop de choses déclenchent des pénalités de suroptimisation. |
| Longueur et profondeur du contenu | Le contenu long est historiquement mieux classé car il couvre davantage de variantes à longue traîne. La longueur doit correspondre au gain d’information réel. |
| Table des matières | Les tables des matières liées à des ancres améliorent l'UX pour les pages longues. Ils fournissent aux robots des liens de saut analysables. Conduit souvent à des liens annexes étendus dans les SERP. |
| Indexation sémantique latente (LSI) | Les termes et synonymes associés prouvent la profondeur du sujet. La correspondance neuronale les utilise pour comprendre le contexte au-delà des phrases exactes. |
| Correspondance d'entité | Dans quelle mesure l’algorithme mappe le sujet de votre page au Global Knowledge Graph. Une correspondance précise décide si vous devenez une source d’IA générative. |
| Récence et mises à jour du contenu | Un multiplicateur de temps s'applique aux requêtes nécessitant de nouvelles données. Les mises à jour structurelles majeures signalent la pertinence. Les ajustements superficiels sont ignorés. |
| Niveau de grammaire et de lecture | Une mauvaise grammaire est en corrélation avec de faibles scores E‑E‑A‑T. Faire correspondre le niveau de lecture à l’intention de recherche améliore l’engagement et le temps d’attente. |
| Intégration multimédia | La vidéo, l'audio et les visuels interactifs optimisés augmentent la profondeur des interactions et le temps passé sur la page. Cela envoie des signaux comportementaux positifs. |
| Structure de liaison interne | Le nombre, la qualité et le texte d'ancrage des liens internes font évoluer le PageRank sur votre site. Ils établissent une hiérarchie de pages importantes. |
Signaux comportementaux, Navboost et boucle de rétroaction implicite
Pendant des années, les experts se sont demandé si les clics des utilisateurs affectaient les classements.
En 2026, le débat est terminé.
Les mesures d’interaction des utilisateurs sont désormais des « signaux bruts » qui déterminent les modificateurs de classement du deep learning.
Des modèles comme Boost de navigation, ClassementIntégrer, et RangIntégrerBERT s'appuyer sur les commentaires implicites des utilisateurs.
Ils utilisent ces commentaires pour ajuster les références de classement et affiner la correspondance générative.
La mécanique des fractions de clics et l’achèvement des tâches
L'algorithme ne récompense pas le volume brut de clics.
Il filtre les clics pour le bruit.
Ensuite, il calcule le rapport entre les interactions réussies et le total des interactions.
La principale différence réside entre un Clic long et un Clic court.
- Clic long – Un utilisateur clique sur un résultat et reste sur le contenu. Ils ne reviennent pas immédiatement aux résultats de la recherche.
- Clic court – Un utilisateur clique et rebondit rapidement.
L'algorithme évalue le Fraction longue clic-à-clic (LCIC):
texte
LCIC = Long Clicks ÷ Total Clicks
Une fraction LCIC élevée signifie que l’intention de l’utilisateur a été satisfaite.
Ces données sont regroupées sur environ 70 jours de journaux de recherche.
C’est pourquoi les changements de classement se produisent sous la forme de changements lents et soutenus, et non de fluctuations quotidiennes.
Le lissage statistique empêche un clic impair de fausser les résultats.
Au-delà de la durée du clic, les algorithmes évaluent également :
- Profondeur de défilement
- Interactions de navigation
- Achèvement de la tâche
Exemple de réalisation d'une tâche :
Un utilisateur recherche, clique sur un résultat et finalise un achat sans lancer une autre recherche.
Cela renforce considérablement la position de la page.
Avec Google Analytics 4 (GA4), les modèles de référencement prédictif peuvent prévoir les changements de comportement de recherche.
Ils utilisent des données d’événements historiques, des modèles de demande saisonnière et des interactions cross-canal.
Les pages qui génèrent systématiquement des conversions à forte intention et de faibles taux de rebond renforcent la résilience algorithmique.
Ils sont protégés d’une grande volatilité.
Infrastructure technique, éléments essentiels du Web et capacité d'exploration
Le référencement technique est la condition préalable absolue à l’indexation et au classement.
Aucun contenu brillant ne peut vaincre une architecture que les robots ne peuvent pas explorer, analyser ou restituer.
En 2026, la performance est régie par le Core Web Vitals cadre.
Il utilise les données réelles du rapport sur l'expérience utilisateur Chrome (CrUX).
L'évolution des éléments essentiels du Web
La réussite de Core Web Vitals ne déclenche pas de pénalité manuelle.
Mais les réussir constitue un facteur déterminant dans un environnement compétitif.
Cela influence également fortement les signaux comportementaux qui déterminent les scores Navboost.
Le plus gros changement : Le délai de première entrée (FID) a été remplacé par l'interaction avec la peinture suivante (INP).
Ce que mesure l'INP :
INP capture la latence de chaque clic, appui et saisie au clavier tout au long du cycle de vie de la visite de la page.
- Bien – INP ≤ 200 millisecondes
- Besoin d'amélioration – 200 à 500 millisecondes
- Pauvre – INP > 500 millisecondes (expérience fortement dégradée)
La plus grande peinture de contenu (LCP) – Mesure le temps de rendu du plus grand élément visible dans la fenêtre.
Seuil : LCP de 2,5 secondes ou plus.
Changement de mise en page cumulatif (CLS) – Quantifie la stabilité visuelle. Pénalise les déplacements inattendus des éléments lors du chargement.
Score conforme : inférieur à 0,1.
Contraintes techniques au niveau du domaine et du site
| Facteur | Comment ça marche en 2026 |
|---|---|
| Architecture du site | Une structure plate et logique aide les robots d'exploration à atteindre efficacement les pages profondes. Des structures complexes enterrent le contenu et gaspillent le budget d’exploration. |
| Certificat SSL (HTTPS) | Des connexions sécurisées sont obligatoires. Les sites HTTP non sécurisés sont confrontés à une suppression de classement et à des avertissements du navigateur. |
| Emplacement et disponibilité du serveur | Les temps d’arrêt fréquents réduisent le taux d’analyse. Les serveurs physiquement proches des chercheurs améliorent la latence de recherche localisée. |
| Plans de site XML | Des plans de site précis et dynamiques garantissent une découverte rapide de nouvelles URL, variantes hreflang et ressources multimédias. |
| Méta-informations en double | Les titres et descriptions redondants confondent les systèmes de clustering. Cela conduit à la cannibalisation (le moteur ne peut pas choisir une version canonique). |
| Optimisation mobile | L’indexation mobile first est universelle. Une stricte parité entre ordinateur et mobile est requise. Le contenu caché derrière les accordéons peut être moins pondéré. |
| Balisage de schéma | Les données structurées (article, personne, entreprise locale, FAQ) transforment le texte non structuré en un format lisible par machine. Cela permet des extraits enrichis et l’inclusion de l’IA. |
Le graphique de backlink et les mécanismes de confiance hors page
Même avec l’essor de l’IA générative, le graphique de backlink reste le principal moyen mathématique de mesurer la confiance des tiers.
Mais l’évaluation a changé.
Il s'agit maintenant qualité, pertinence contextuelle et diversité des réseaux- pas la quantité.
Des milliers de liens vers des annuaires de bas niveau ou des spams de forums ne sont plus utiles.
Les systèmes avancés de reconnaissance de formes réduisent activement le TrustRank d’un site lorsqu’ils détectent de tels modèles.
Qualité des liens et pertinence contextuelle
Un backlink provenant d’un domaine faisant autorité et mondialement reconnu dépasse les centaines provenant de sources obscures.
L'algorithme vérifie également pertinence thématique:
- Un lien provenant d’une niche étroitement liée fournit une valeur sémantique concentrée.
- Un lien hors sujet ne donne presque aucune équité.
Le placement des liens est important :
Les liens contextuels à l’intérieur du texte du corps éditorial ont beaucoup plus de poids que les liens dans les pieds de page, les barres latérales ou les biographies des auteurs.
Le système évalue également cooccurrences-le texte entourant le backlink.
Il extrait la pertinence contextuelle même lorsque le texte d'ancrage lui-même est générique.
| Facteur de backlink | Comment ça marche en 2026 |
|---|---|
| Lier les domaines racines et les adresses IP | De nombreux liens provenant de divers domaines racine et de différentes adresses IP de classe C prouvent une autorité organique. Les liens du même bloc IP déclenchent des filtres PBN. |
| Texte d'ancrage du backlink | Le texte d'ancrage donne un contexte explicite. Mais les profils de correspondance exacte répétitifs sont signalés comme manipulation. Un profil naturel utilise des ancres de marque, de navigation et de correspondance d'expression. |
| Domaines .EDU et .GOV | Ces domaines ont un TrustRank massif en raison d'un enregistrement strict. Leurs backlinks sont des signaux de validation très convoités. |
| Vitesse du lien | Une vitesse de liaison positive constante et naturelle signale une pertinence continue. Des pics soudains de liens de mauvaise qualité déclenchent des rétrogradations ou des révisions manuelles. |
| Lien vers la diversité | Un profil sain contient un mélange réaliste d'attributs « dofollow », « nofollow », « sponsorisé » et « UGC ». Cela simule la croissance naturelle du Web. |
| Listes organisées et Wikipédia | Être cité comme source vérifiée sur Wikipédia ou dans des rapports d'experts donne un énorme TrustRank. Il agit comme une puissante vérification d’entité. |
| Mauvais quartiers | Les liens provenant d’hôtes de logiciels malveillants, de fermes de liens ou de domaines pénalisés génèrent une équité négative. Auditez vos backlinks et utilisez l’outil Disavow pour couper les liens toxiques. |
Recherche multimodale : visuel, vocal et signal vibratoire
L'écosystème de recherche 2026 ne se limite pas au texte.
Les interfaces multimodales nécessitent une optimisation des dimensions visuelles, auditives et contextuelles.
Une stratégie textuelle ne capture qu’une fraction de l’intention de l’utilisateur.
Recherche visuelle et optimisation d'image
Les requêtes visuelles (pilotées par Google Lens) représentent plus de 22 % de toutes les recherches sur le Web.
La croissance annuelle dépasse 30%.
Les algorithmes s'appuient sur des couches de métadonnées interconnectées, des données de fichiers intégrées et des réseaux neuronaux avancés de reconnaissance d'images.
Format – AVIF est fortement favorisé. Il crée des fichiers jusqu'à 50 % plus petits que les fichiers JPEG équivalents. WebP est la solution de secours secondaire.
Résolution – Minimum 1 200 pixels sur le bord le plus long. Cela qualifie vos images pour une indexation avancée dans les résultats Google Discover et Lens.
Triangulation contextuelle détermine le classement.
Le moteur de recherche corrèle :
- Texte alternatif descriptif
- Données EXIF intégrées
- Dénomination logique des fichiers
- Texte environnant sur la page
Lorsque ceux-ci s'alignent sur le balisage Product ou ImageObject Schema, votre image devient une entité faisant autorité et consultable.
Optimisation de la recherche vocale et du moteur de réponse
27 % de la population mobile mondiale utilise activement la recherche vocale.
Pour classer la voix, vous avez besoin de Optimisation du moteur de réponse méthodes.
Vitesse – Les pages de réponse vocale se chargent en 2,68 secondes en moyenne. C'est 52 % plus rapide que les pages standard. Le non-respect des seuils de vitesse vous disqualifie, quelle que soit la qualité du contenu.
Structure – Les algorithmes privilégient le contenu qui capture les extraits de code « Position 0 ».
Donnez des réponses directes et concises aux questions conversationnelles à longue traîne dans les 40 premiers mots. Cela capture la part la plus élevée de citations vocales.
Intention locale – 58 % des recherches vocales ont une intention locale spécifique.
Maintenir un schéma NAP (nom, adresse, téléphone) granulaire. Gardez des listes d’annuaire cohérentes. Conservez un profil d'entreprise Google optimisé. Ceux-ci ne sont pas négociables.
Le facteur Vibe et la continuité du signal multiplateforme
Une nouvelle et puissante dynamique de classement est la Facteur « ambiance ».
Il s'agit d'un signal multimodal. Il évalue le ton émotionnel, contextuel et esthétique du contenu de votre entité sur l’ensemble d’Internet.
Les algorithmes analysent :
- Clarté audio
- Composition visuelle
- Modèles de comportement multiplateformes
Ils regroupent le contenu en profils thématiques généraux.
La domination de la recherche nécessite un écosystème de signaux unifiés.
Lorsque votre marque maintient une « ambiance » cohérente (le même ton autoritaire, la même esthétique visuelle et les mêmes thèmes parlés dans YouTube Shorts, Instagram Reels et la vidéo de votre site Web), vous déclenchez une confiance algorithmique multiplateforme.
Si l’algorithme reconnaît un utilisateur interagissant avec un modèle visuel spécifique sur une plateforme sociale, il devient beaucoup plus susceptible de suggérer cette marque dans des environnements de recherche ou génératifs traditionnels.
Application algorithmique : SpamBrain et sanctions politiques
Tout au long de l’année 2026, les mises à jour algorithmiques montrent une position agressive, basée sur l’IA, contre la manipulation.
Les mises à jour principales et anti-spam de mars 2026 ont été améliorées. SpamCerveau protocoles de détection.
Ils ont neutralisé les tactiques de référencement synthétique à l’échelle mondiale.
Ils ont exécuté les déploiements à une vitesse sans précédent.
Ce sont mises à jour basées sur l'application.
Ils suppriment définitivement les avantages acquis grâce aux violations des politiques.
Important : Le simple fait de désavouer les mauvais liens ou de supprimer les pages incriminées ne restaurera pas votre classement d'origine.
Les fondations artificielles ont été supprimées.
Abus ciblés et rétrogradations algorithmiques
Abus de contenu à grande échelle
Cible les domaines produisant en masse des pages peu originales et de faible valeur.
La pénalité recherche :
- Pas de contrôle éditorial humain
- Pas de rapport original
- Faible gain d’informations
- Automatisation utilisée pour créer un contenu superficiel qui ne satisfait pas l'intention
Abus de réputation de site (parasite SEO)
Cela se produit lorsqu'un domaine de haute autorité publie du contenu tiers sans aucun rapport, juste pour transmettre des signaux de classement.
La politique de 2026 ignore les allégations d’« implication de première partie » si le contenu est déconnecté de l’entité sémantique principale du domaine hôte.
Abus de domaine expiré
L’algorithme identifie et dévalorise les domaines expirés achetés pour réutiliser d’anciens profils de backlinks vers des niches sans rapport et de mauvaise qualité.
Modèles de liens manipulateurs et masquage
Les fermes de liens automatisées, les redirections sournoises et le masquage entraînent des rétrogradations graves, souvent permanentes.
La récupération nécessite des mois de données comportementales durables et conformes.
SEO international et géolocalisation des entités
L’expansion mondiale en 2026 nécessite une précision bien au-delà de la traduction linguistique.
Le référencement multilingue est régi par des systèmes de recherche d’informations multilingues très sensibles.
L’exigence fondamentale : implémentation parfaite du hreflang.
Cela garantit que l'algorithme diffuse l'URL localisée correcte en fonction des paramètres régionaux d'adresse IP et de langue du navigateur.
Mais l’hygiène technique ne suffit pas à elle seule.
Les algorithmes font désormais la différence entre traduction littérale et une véritable localisation culturelle.
Vos pages doivent :
- Adaptez-vous aux tendances localisées du volume de recherche
- Incorporer des idiomes culturels
- Répondre à l’intention spécifique à la région
Les traductions générées par l’IA sans surveillance humaine produisent une « localisation uniquement par traduction ».
L’algorithme 2026 les pénalise en tant que contenu léger s’ils manquent :
- Signaux spécifiques aux entités régionales
- Backlinks locaux authentiques
- Balisage de schéma régional précis
Conseil technique :
Déployez un réseau de diffusion de contenu (CDN) ou un hébergement de serveur localisé.
Cela maintient vos seuils Core Web Vitals maintenus à l’échelle mondiale.
Cela empêche une latence élevée de dégrader les signaux de classement comportemental international.
Contraintes au niveau du domaine et règles d'algorithme spéciales
Avant d’évaluer la sémantique de la page, l’algorithme vérifie la santé globale, l’historique et l’intégrité structurelle de votre domaine racine.
| Facteur de domaine | Comment ça marche en 2026 |
|---|---|
| Âge et histoire du domaine | Les domaines plus anciens ont accumulé des données d'interaction historiques et une stabilité d'entité. Les nouveaux domaines sont confrontés à une période de filtrage provisoire « bac à sable ». Une propriété irrégulière ou des sanctions manuelles antérieures déclenchent une surveillance accrue. |
| Durée d'enregistrement du domaine | Les domaines enregistrés pendant plusieurs années consécutives témoignent d’un engagement à long terme. Cela vous distingue des tactiques de spam « churn-and-burn ». |
| Mot-clé dans TLD | Un mot-clé principal dans le nom de domaine donne un signal mineur de pertinence lexicale. Mais son poids a été réduit. Les domaines de correspondance exacte de faible qualité ne sont plus classés uniquement en fonction de leur nom. |
| TLD spécifique à un pays | Une extension localisée (.ca, .co.uk) améliore considérablement la visibilité locale. Mais cela limite votre capacité à vous classer à l’échelle mondiale en dehors de cette région. |
Algorithmes conditionnels spéciaux
Votre argent ou votre vie (YMYL)
Les questions concernant les finances, la santé médicale, les conseils juridiques et la sécurité font l’objet d’évaluations E‑E‑A‑T beaucoup plus strictes.
Les auteurs non vérifiés sont systématiquement bloqués dans le classement de ces sujets.
La requête mérite de la fraîcheur (QDF)
Un multiplicateur de visibilité temporaire mais important est appliqué aux actualités tendances ou aux pics soudains de volume de recherche.
Les anciennes pages faisant autorité sont contournées au profit d’un contenu très actuel.
Pénalités DMCA
Les domaines faisant l'objet de plusieurs demandes valides de retrait pour atteinte aux droits d'auteur sont systématiquement supprimés des classements.
Signaux sociaux et vitesse des entités
D’ici 2026, la relation entre les réseaux sociaux et le classement sera clairement définie.
Les signaux sociaux (j’aime, partages, retweets, nombre de followers) sont des facteurs de classement strictement indirects.
Un nombre élevé de followers ne renforce pas directement l’autorité.
Cependant, le effet d'entraînement de la vitesse sociale est un catalyseur organique essentiel.
Voici comment cela fonctionne :
- Le contenu à fort engagement sur LinkedIn, X (Twitter) et Reddit accélère la découverte des robots. Cela garantit une indexation rapide.
- La distribution sociale virale réduit considérablement le « délai d’obtention du premier backlink ». Le contenu largement partagé atteint les journalistes et les créateurs. Ils s'y connectent ensuite à partir de leurs propres domaines. Ces backlinks éditoriaux influencent directement et puissamment les classements.
Une forte promotion sociale stimule également volume de recherche de marque.
Les utilisateurs recherchent un nom de marque après l’avoir rencontré socialement.
Les systèmes d'apprentissage automatique mappent ensuite cette marque à son groupe thématique principal dans le Knowledge Graph.
Ce comportement indique une demande externe élevée et une confiance dans l’entité.
Il fournit un impact algorithmique substantiel à toutes les requêtes associées sans marque.
Conclusion : les trois piliers de la visibilité 2026
L’algorithme de recherche 2026 n’est pas une liste de contrôle statique.
Il s’agit d’un écosystème dynamique axé sur les réseaux neuronaux.
Il évalue l'intention, la confiance et le comportement en temps réel.
Pour obtenir une visibilité dominante, vous devez exécuter simultanément trois disciplines qui se croisent.
Pilier 1 : Perfection technique absolue
- Les domaines doivent être analysés efficacement.
- Passez les seuils stricts de Core Web Vitals (INP inférieur à 200 millisecondes).
- Utilisez un balisage Schema complet pour fournir un contexte lisible par machine.
Pilier 2 : Contenu E‑E‑A‑T humain
- Allez au-delà de la correspondance de mots clés.
- Démontrer ouvertement son expérience.
- Fournissez un gain d’informations explicites grâce à une expérience vécue, des données propriétaires et un clustering sémantique approfondi.
- Servir un double objectif :
- Un document immersif qui suscite un engagement comportemental profond (fractions de clics longs élevées) pour les SERP traditionnels.
- Une ressource hautement structurée et facilement extractible pour les LLM Generative Engine.
Pilier 3 : Création d’une entité de marque
Cela a complètement remplacé la création de liens isolés.
- Cultivez une empreinte numérique généralisée de mentions de marque non liées.
- Gagnez des backlinks contextuels de haute qualité.
- Maintenez des signaux « vibe » multimodaux cohérents sur toutes les plateformes.
Lorsque vous faites les trois, vous créez un fossé algorithmique insurmontable.
Conclusion finale
À une époque où les aperçus de l'IA satisfont une intention d'information immédiate sans un clic,
optimiser pour devenir le entité vérifiée et fiable derrière la réponse synthétisée de l’IA
est le facteur de classement définitif du Web moderne.