検索が変わりました。 2026 年、AI があなたを引用し、アルゴリズムがあなたを信頼し、人間があなたを瞬時に理解すると、あなたはランク付けされます。
このガイドでは、最新のページ上の要素をすべてカバーします。から 技術的基礎 生成エンジンの最適化まで。これを読んだ後は、別のリソースは必要ありません。
私たちは何年にもわたってアルゴリズムのアップデートを行ってきましたが、 何百ものケーススタディ、 そして 2026 年のベスト プラクティス 1 つの決定的なガイドにまとめられます。
1. 新たな現実: オンページ SEO が永遠に変わってしまった理由
検索エンジンの最適化 青いリンクは約 10 個ではなくなりました。
私たちは現在、マルチモーダルな発見の世界に住んでいます。大規模言語モデル (LLM) は情報の門番です。
Google の AI モード、AI 概要、Perplexity、ChatGPT 検索は、ページをクロールするだけではありません。彼らは信頼できる情報源から回答を合成、解釈し、抽出します。
この変化により、「ゼロクリック」検索が生まれました。現在、クエリの約 60% はクリックなしで終了します。
AI 概要だけでも、標準結果のオーガニック クリックスルー率が 61% 低下しました。
従来の第 1 位の地位は、前年比 32% 減少しています。
しかし、これは災害ではありません。
AI 概要内でコンテンツが引用されると、無視された上位ページと比較してクリック数が 35% 増加します。
また、AI が信頼する情報源となることで、研究段階でブランド認知度が高まります。これにより、トラフィックの品質が向上し、より良いトラフィックが実現されます。 コンバージョン率.
2026 年のあなたの仕事は明らかです。 2 人の読者向けにすべてのページを同時に設計します。
- 人間の読者 魅力的で信頼できるエクスペリエンスが必要です。
- 機械 構造化されたセマンティックな情報が必要です。 簡単に抽出できるアーキテクチャ.
このガイドでは、両方の方法を説明します。孤立したキーワード ターゲティングが残されてしまいます。生成エンジン最適化 (GEO)、応答エンジン最適化 (AEO)、および揺るぎない話題の権威を採用します。
2. 私たちがここにたどり着いた経緯: アルゴリズムのタイムライン (2023 ~ 2026 年)
現在何が機能しているかを理解するには、パターンを見てください。
Google は、年に 2 回のコア アップデートから、3 か月ごとのほぼ継続的な再調整に移行しました。
2023 – 4 月のレビュー更新では、直接の経験が非常に重要視されました。 「専門家が書いたコンテンツ」の時代が始まった。
2024 – AI が生成した概要 (Gemini を利用) がユーザーの行動を変えました。従来のSERP機能は縮小し始めました。
2025 年後半 – 不安定な移行。 Google は、AI が生成した綿毛を検出する能力を向上させました。
2026年3月 – 決定的な瞬間。調整されたスパム更新とコア更新が同時にヒットしました。彼らはランキングの状況を永久に再構築しました。
持ち帰りは?アルゴリズムは単一の変数を考慮しなくなりました。
彼らは専門知識、独創性、構造的完全性を総合的に評価します。
大量の AI コンテンツ、時代遅れの技術的トリック、または薄いページを使用してシステムを騙そうとした場合、回復することはできません。
このガイドは 1 つの原則に基づいて構築されています。それは、本物の専門知識、実際の経験、マルチプラットフォームでのブランド プレゼンスという、Google が今日提供しているものに合わせることです。
3. 2026 年 3 月の地震: スパム アップデート + コア アップデート
最新のオンページ SEO について知っておくべきことはすべてここから始まります。
2026 年の初めに、Google は次のような「ワンツーパンチ」を開始しました。
- 記録的な速さのスパム更新
- 直後に広範なコアアップデートが続く
これは意図的なものでした。 Googleはまず操作的なコンテンツを削除した。次に、他の全員の品質のしきい値をリセットします。
スパムアップデート (2026 年 3 月 24 日~4 月 5 日)
Google の最も積極的な取り締まりは、外科的精度で 3 件の不正行為を対象としました。
- 大規模な AI コンテンツの悪用 – 大量の一般的な未編集の AI コンテンツ (編集監督なし) を公開するドメインは、トラフィックの 60 ~ 80% を失いました。
- 期限切れのドメイン操作 – 再利用された古いドメイン(リンクの公平性のためだけに購入された)上に構築されたサイトは降格されました。
- サイトの評判の悪用 (パラサイト SEO) – 権限のあるドメインでホストされている低品質のサードパーティ コンテンツが体系的に除外されました。
メッセージ: 値のないボリュームは無効です。
コア アップデート (2026 年 3 月 27 日以降)
このアップデートにより、信号の重み付け方法が根本的に変更されました。見出しが変わります:
- E‑E‑A‑T は世界共通になりました。 YMYL (Your Money or Your Life) トピックに限定されなくなりました。現在では、すべてのページが経験、専門知識、権威性、信頼性によって評価されます。
- アフィリエイト サイトは壊滅しました。 71% で大幅な減少が見られました。 Google は、集約された概要よりも直接の体験を優先しました。
- Core Web Vitals は複合スコアになりました。 読み込み速度、インタラクティブ性、視覚的な安定性が、ランキングに直接影響する 1 つのパフォーマンス要素に集約されるようになりました。
新しいベースライン: 完璧な技術的パフォーマンスは、エントリーチケットにすぎません。
AI の概要や上位のオーガニックスポットに実際にアクセスできるのは、実際に実証された直接の経験と深い話題の権威です。
4. オンページ SEO の構造的基盤
一言も書く前に、足場を正しく整えましょう。
2026 年には、HTML 構造とメタデータが、従来のクローラーと LLM インジェストの両方にとって主要な解析レイヤーになります。
意図の調整: アルゴリズムの最初のフィルター
検索エンジンは単語ではなくソリューションをランク付けします。
ページのフォーマット、トーン、深さがユーザーが実際に求めているものと一致しない場合、キーワードをいくら調整しても救いにはなりません。
すべてのクエリは、次の 4 つのバケットのいずれかに分類されます。
| 意図 | 主な目標 | 最適なコンテンツアーキテクチャ |
|---|---|---|
| 情報提供 | 深い知識、問題解決 | 長い形式のガイド、モジュール式の FAQ セクション、AI 抽出用に構築されたエンティティ豊富なチュートリアル |
| ナビゲーション | 特定のブランドまたは場所を検索する | 合理化されたホームページ、ハイパーローカルなランディング ページ、明確なブランド エンティティの宣言 |
| コマーシャル | オプションを比較し、レビューを読む | 並べた表、オリジナルのメディアによる実践レビュー、長所/短所のマトリックス |
| トランザクション | 購入、ダウンロード、サインアップ | スムーズな商品ページ、最適化されたチェックアウト フロー、目立つ CTA、豊富な商品スキーマ |
すでにランキングされているものを常にリバース エンジニアリングしてください。
ターゲット クエリの上位の結果と AI 概要から、アルゴリズムの予想が明らかになります。
次に、より深いサブトピックに展開する前に、最初の 2 ~ 3 文で主な質問に直接答えます。
URL の最適化: 簡潔、説明的、セマンティック
URL は依然として軽量のランキング シグナルおよび信頼の手がかりです。ベストプラクティス:
- ストップワード (「and」、「the」、「of」) を削除します。
- 構造をフラットに保ちます (論理レベルの深さは 3 つ以下)
- 主なキーワードを自然に含める
- パラメータベースの重複 URL を排除します (大規模なサイトではパラメータの無駄がクロール予算の 30% 以上を消費します。正規化を使用します)
タイトルタグとメタディスクリプション: オーガニック広告コピー
タイトルタグ – 主要なコンセプトを前面に置きます。 60 文字以内にしてください。説得力のある独自の価値提案を含めます。これは依然として最も強力な直接関連性シグナルです。
メタディスクリプション – ランキング要素ではありませんが、無料の広告です。 105 ~ 160 文字以内にしてください。二次キーワードを自然に組み込みます (SERP では太字になる場合があります)。常に明確な行動喚起を含めてください。 AI 検索プラットフォームでは、関連性を検証するためにクリック データを使用することが増えています。高い CTR は可視性を直接サポートします。
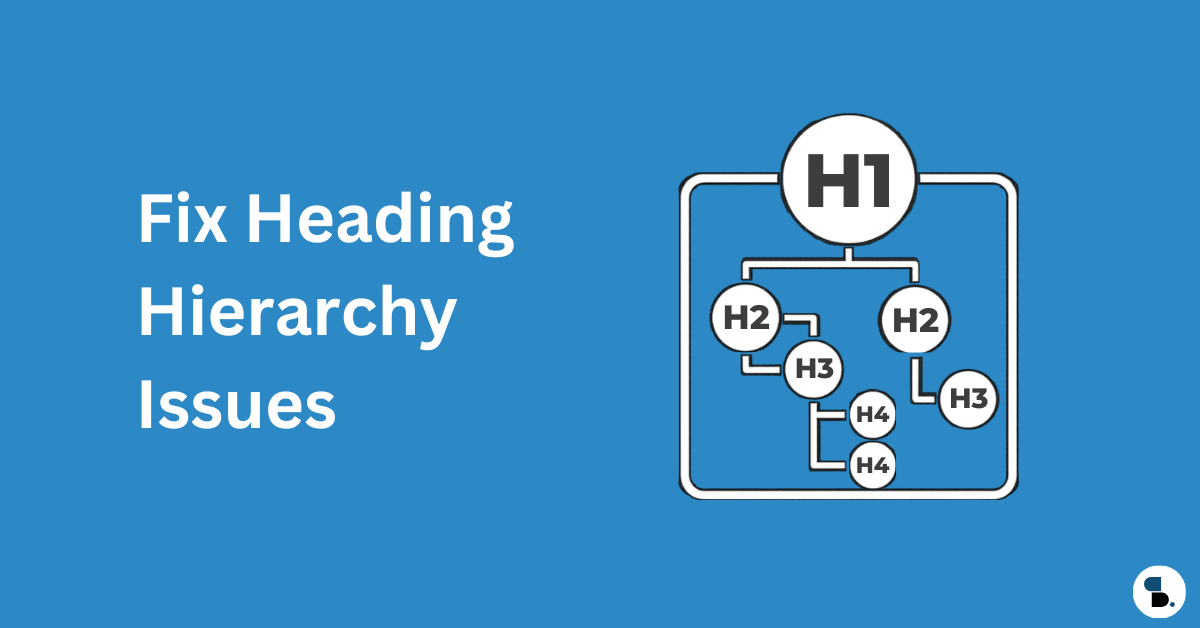
見出し階層: LLM の青写真
H1 ~ H6 構造は単なる書式設定ではありません。これは、LLM が回答を抽出するために使用するセマンティック マップです。
- H1 はタイトル タグを厳密に反映し、ページの単一のトピックを定義する必要があります。
- 小見出しは説明的であり、自然言語クエリと一致する必要があります。 「はじめに」や「ステップ 1」などの一般的なラベルは避けてください。
- 質問ベースのヘッダーを使用します。例: 「Shopify ストアのコア ウェブ バイタルを最適化する方法」。これは、AI モデルがクエリを特定のセクションにマッピングするのに役立ちます。
5. E‑E‑A‑T: 信頼のアーキテクチャ
このアルゴリズムは、経験、専門知識、権威性、信頼性を単一の交渉不可能なフィルターとして扱うようになりました。
信頼が基盤です。これがないと、他のすべての信号が無視されます。
あなたが本物であることを証明する方法は次のとおりです。
「体験」シグナル: 伝えるのではなく、見せる
最初の「E」には特別な重みが加わりました。 Google の品質評価者は、あなたが話していることを実際に実行したという明確な証拠を探します。
これはつまり:
- オリジナルメディア – 独自の写真、未編集のビデオデモンストレーション、カスタムデータの視覚化
- 特定の逸話と文書化された失敗 – LLM が幻覚を起こせない洞察
- 独自の調査、ケーススタディ、独自のデータ – これらによりあなたが一次情報源となり、AI が引用される可能性が高まります
優先順位付けマトリックス: トラフィックが多く、機会が多いページに焦点を当てます。現実世界のデータと専門家の視点を注入します。決して偽りの経験信号を出さないでください。 AI モデルはセマンティックの不一致を簡単に発見します。
著者エンティティ: オプションから必須へ
匿名性はランキングを殺します。すべてのコンテンツは、検証可能な人間の専門家と関連付けられている必要があります。
以下を使用して専用の著者ページを構築します。
- 正式な正式名と職業上の顔写真
- 資格、学歴、所属業界
- ドメイン上のすべての記事のインデックス
次に、そのアイデンティティを外部から裏付けます。著者のサイト上の経歴を LinkedIn、業界団体のプロフィール、および他の権威あるサイトの署名付き記事にリンクします。
検索エンジンが複数の信頼できるノード間で作成者のフットプリントを相互参照できる場合、コンテンツは大きなベースライン信頼スコアを継承します。
6. 言語の最適化: マシンフレンドリーなコンテンツの数学
LLM は、読みやすさ、意味の密度、明瞭さを評価します。
コンテンツが専門用語が多く入り組んだ文章である場合、摩擦が生じ、引用されなくなります。
可読性が重要な数式
公開する前に次のメトリクスを使用して、最適な抽出しきい値内に確実に収まるようにします。
- フレッシュの読みやすさスコア – 高いほど簡単です。一般向けでは60点以上を目指します。テクニカル B2B では 50 以上を目指します。
- フレッシュキンケイドのグレードレベルと ARI – 幅広い内容については 8 年生から 10 年生を対象としています。専門的なトピックについては 12 位以上を目標にします (ただし、絶対に必要な場合を除き、14 位を超えないでください)。
- ガンニングフォグ指数 – 多音節の単語を罰します。技術的な内容の場合は 12 未満に保ってください。大規模なアピールの場合は 10 未満に抑えてください。
文の長さと理解力
2026 年の分析データは、鋭い相関関係を示しています。
| 平均的な文の長さ | 理解 |
|---|---|
| 8単語まで | 100% |
| 11の単語 | 90% |
| 17単語 | 75% |
| 21単語 | 40% |
| 25 語以上 | 24%以下 |
ベストプラクティス:
- 短い段落を使用します (最大 2 ~ 3 行)
- 会話的な口調を使う
- キーワードスタッフィングをゼロにする
クリーンでアクセスしやすい言語により、LLM は高い信頼性で事実を抽出できます。
7. 生成エンジン最適化 (GEO): AI 抽出のためのエンジニアリング
AI 検索エンジンはページ全体をレンダリングしません。モジュール化されたチャンクをプルします。
コンテンツはすぐに取り込めるように構造化されている必要があります。
セマンティックチャンク化と「答えを導き出す」
長い形式のコンテンツを個別のセクションに分割します。各セクションの先頭には、ユーザーに特定の質問をする H2 または H3 を付ける必要があります。
次に、見出しの直後の最初の文は、40 ~ 60 語で直接的かつ決定的な答えを与える必要があります。その後、コンテキスト、例、詳細を説明します。
この逆ピラミッド構造は次の 2 つのことを行います。
- これは、即時抽出に対する LLM のニーズを満たします。
- 人間のスキャナーには深みが与えられます。
マシン用のフォーマット
- 引用可能な文を使用します。AI がそのまま反映できる完全で事実に富んだ文です。
- ステップ、ランキング、機能にはリスト (順序付きおよび順序なし) を使用します。ただし、記事全体を箇条書きにしないでください。
- かつてキャプチャされた注目のスニペットの手法が、AI 概要に直接適用されるようになりました。簡潔な定義とデータを各セクションの上部近くに配置します。
重要なのは、コンテンツ配信に JavaScript に依存しないことです。多くの LLM クローラー (GPTBot、ClaudeBot、PerplexityBot) は、複雑なクライアント側スクリプトを実行できません。重要なコンテンツは、最初のリクエストの生の HTML DOM に存在する必要があります。
8. 局所的権威: ハブアンドスポークモデル
孤立したページはランク付けされなくなりました。 Google は、サイト全体で主題がカバーされているかどうかを評価します。
優位に立つには、相互接続されたコンテンツ クラスターが必要です。
コンテンツクラスタの実装
- ピラーページ (ハブ) – 中心となるトピックの包括的かつ広範な概要。競争力のある部分一致キーワードをターゲットにします。
- クラスターページ (スポーク) – 狭いサブトピック、ロングテール クエリ、および関連する FAQ に関する詳細な記事。
内部リンク: コンテキスト ブリッジ
- ピラー ページはすべてのクラスター ページにリンクしています。
- すべてのクラスター ページは、説明的でキーワードが豊富なアンカー テキストを含むピラーにリンクされています。
- クラスタ ページは、意味的に関連する場合に相互リンクします。
この構造は、PageRank を渡すだけではありません。これは、機械学習アルゴリズムの専門知識のセマンティック境界を定義します。
適切に相互リンクされたクラスターは、オーガニック トラフィックを 30% 増加させ、孤立した投稿よりも 2.5 倍長くランキングを維持します。
1,000 単語あたり 2 ~ 5 個のコンテキスト リンクを目指します。
クロールの効率と 3 クリック ルール
すべての重要なページは、ホームページから 3 回のクリック以内でアクセスできる必要があります。
アーキテクチャをフラット化すると、クロール効率が 40 ~ 70% 向上します。 4 レベルより深いページがランク付けされることはほとんどありません。
また、薄くて古いコンテンツを積極的に削除 (またはインデックスなし) します。これにより、サイト全体の品質密度が向上します。デッドウェイトを削除すると、残りのページのアルゴリズムによる評価が上がります。
9. 技術的なオンページ SEO: コア Web バイタルと INP マスタリー
技術的な卓越性はフロアにあります。
2026 年 3 月のアップデートにより、Core Web Vitals が複合スコアになりました。現在最も重要な指標は、Interaction to Next Paint (INP) です。
INP が測定するもの
INP は First Input Delay (FID) を置き換えました。
ページのライフサイクル全体を通じて、すべてのユーザー インタラクション (クリック、タップ、キーボード入力) の遅延を監視します。最悪の値を報告します。
「良好」評価には、すべての負荷にわたって 75 パーセンタイルで 200 ミリ秒以内のフィードバックが必要です。
200 ~ 500 ミリ秒のスコアは改善の必要があります。
500 ミリ秒を超えるスコアは貧弱であり、ランキングを直接的に抑制します。
INPを最適化する方法
- 長いタスクを分割する – 大きな JavaScript バンドルを分割します。必須ではないサードパーティのスクリプト (マーケティング タグ、ヒートマップ) は、最初のインタラクションが終わるまで延期します。負荷の高い計算を Web ワーカーにオフロードします。
- 高周波イベントをデバウンスする – 動的入力の場合、コールバック ストームを防ぐために 150 ~ 300 ミリ秒のデバウンスを使用します。
- DOM サイズを削減する – 膨張により大規模なスタイルの再計算が強制されます。 DOM に 1,400 を超えるノードがある場合は、深くネストされたコンテナーをリファクタリングし、アコーディオンを簡素化し、UI ライブラリを監査します。
- 即座に視覚的なフィードバックを提供する – バックグラウンド データを処理する前に、ローディング スピナーまたは状態変更を即座に表示します。これにより、応答性の認識が満たされます。
10. 高度なスキーマ マークアップ: エンティティ グラフ
構造化データは、リッチスニペットの餌から、AI にとって重要な信頼層と取り込み層に進化しました。
2026 年の焦点は、エンティティの曖昧さの排除とインテント一致スキーマにあります。
今使用するスキーマ
一般的な FAQ とハウツーのリッチリザルトは制限されています。拡張された SERP 機能をトリガーするスキーマ タイプは、依然として約 31 種類のみです。
優先順位:
- 組織と人物 – 発行者と著者の実体を完全な詳細とともに確立します。
- 記事 + 著者 – すべての記事を検証済みの人物エンティティにリンクします。
- 同じプロパティ – エンティティを Wikidata、Crunchbase、LinkedIn などに接続します。一致する信頼できる外部ソースが多いほど、エンティティの信頼スコアは高くなります。
- について知っています – 組織/個人スキーマ内で、専門とするトピックと概念を宣言します。これは、AI ソース選択のための直接的なトピックの権威シグナルです。
地域固有のスキーマ
- クレームレビュー – 事実確認または研究内容の場合。信頼性の高さを示します。
- 定義された用語 – 用語集と技術的な定義について。テキストを正式な定義として明示的にマップします。
スキーマは常に、表示されているコンテンツと正確に位置合わせしてください。ユーザーが目にするものと一致しないマークアップ (偽のレビュー、誇張された評価、間違ったタイプ) は「誤解を招く」ものとして分類され、ペナルティが適用されるようになりました。
11. マルチモーダルおよびビジュアル検索の最適化
ビジュアル検索は爆発的に増加しています。 Google レンズは毎月 200 億件以上の検索を処理し、毎年 30% 増加しています。
画像がマシン ビジョン用に最適化されていない場合、このチャンネルでは表示されません。
視覚的な堀の構築
一般的なストック写真を、アルゴリズムが一貫してブランドと関連付けることができるオリジナルの高品質画像に置き換えます。
e コマースの場合、完全な「見た目」を示すライフスタイル写真が「見て、スナップして、購入する」行動を促進します。
技術的な画像の最適化
- 解像度とフォーマット – 最小幅 1200 ピクセル。 WebP または AVIF (JPEG より 35% 小さい) を使用します。ファイルサイズは200KB未満。
- オブジェクト中心の構成 – 背景をきれいにします。 3 ~ 4 つの角度を使用すると、あらゆる視点からのオブジェクトの認識が容易になります。
- メタデータの調整 – ハイフンで区切られた、キーワードが豊富なファイル名 (例:
matte-black-espresso-machine.webp)。最大 125 文字の代替テキスト。主要な属性がフロントローディングされます。最適化された代替テキストを含む画像は、視覚的な表面からのクリック数が 12.5 倍増加します。 - 配置 – キー画像はスクロールせずに見える範囲に配置し、関連するテキストで囲む必要があります。 Lens の上位検索結果の 3 分の 1 は、このプレミアム プレースメントによるものです。
- 構造化データオーバーレイ – 製品イメージをライブ製品スキーマ (価格、在庫状況、通貨) に接続します。これにより、Lens はショッピング データを画像に直接オーバーレイできるようになります。
12. 音声検索の最適化: 会話型 SEO エコシステム
音声検索は、明確で意図の高いチャネルです。音声クエリは長く、質問ベースで、非常にローカルなものです。
アシスタントの市場シェアが重要なのは、アシスタントがさまざまなインデックスから取得しているためです。
| アシスタント | インデックスソース | ローカルデータソース | 市場占有率 |
|---|---|---|---|
| Googleアシスタント | Google検索 | Google ビジネス プロフィール | 36% |
| シリ | ビング | アップルマップ | 28% |
| アレクサ | ビング | Yelp | 18% |
| コルタナ | ビング | Bing プレイス | 8% |
| サムスン・ビクスビー | ビング | Googleマップ | 6% |
声で勝つ方法
通常、音声アシスタントは 1 つの回答を読み上げます。多くの場合、注目のスニペットまたは AI 概要から抽出されます。その場所を確保しなければなりません。
- 会話的なロングテールの質問をターゲットにします。順番に答えられるようにコンテンツを構成します。
- 直接的で簡潔な回答 (最大 2 ~ 3 文) を質問ベースの見出しの直後に配置します。
- 短い段落、口述しやすいリスト、明確な言葉を使用します。
音声 + ローカル SEO: 76% の要素
「近くにいますか」という質問が多くの声を占めています。ローカル音声検索を実行するユーザーの 76% は 24 時間以内に店舗を訪問します。
主なアクション:
- Google ビジネス プロフィールを完全に最適化します (Google アシスタント用)。
- Web 全体で NAP の一貫性を確保します。
- Q&A セクションに音声による質問の回答を追加します。
- すべてのレビューに返信して、積極的なビジネス関与を示します。
13. 監査、回復、先を行く
継続的なメンテナンスについては交渉の余地がありません。
最新のオンページ監査では、技術インフラストラクチャ、コンテンツ品質、E-E-A-T 信号、AI クロール動作をカバーする必要があります。
サーバーログファイルの分析
フロントエンド クローラーだけでは十分ではありません。ログを分析して、Googlebot と AI 固有のボット (GPTBot、ClaudeBot、PerplexityBot) がどのようにやり取りしているかを正確に確認します。
探す:
- サイトマップ内のクロールされていない正規 URL – 多くの場合、内部リンクが弱いことが原因です。孤立したページをクラスタに再統合します。
- LLM トレーニングのために実際にどのページが取り込まれているか – これにより、AI が価値があると考えるものが明らかになります。
コンテンツ品質スコアリング
アルゴリズムがヒットした後、情報利得の 5 つの側面ですべてのページにスコアを付けます。
- オリジナルデータ
- 検証済みの専門知識
- 実際の体験
- 物質の深さ
- 話題の関連性
それから:
- 強力なページ – 更新されたデータで強化します。
- 弱いページ – 資格のある専門家に書き直してもらいます。
- 重なっているページ – 共食いをなくすために統合します。
- 自重 – 410 ステータス コードでプルーニングします。
コアアップデートのリカバリワークフロー
2026 年 3 月スタイルのコア アップデートからの回復には数か月かかります。このタイムラインに従ってください:
- 第 1 ~ 2 週目 – Search Console でドロップを確認します。影響を受けるページを特定します。自重を取り除きます。
- 2~3週目 – 競合するページを統合します。内部リンククラスターを改良します。
- 3~6週目 – 独自の洞察と検証された作成者によって、生き残っているコンテンツを強化します。すべての Core Web Vitals (特に INP) を修正します。
その後、6 ~ 12 週間インプレッションの傾向を監視します。
インプレッションの回復はクリックの回復に先行します。サイト全体の品質への取り組みを実証している場合、完全な復元は通常、次の広範なコア更新と同時に行われます。
2026 年の究極のオンページ SEO チェックリスト
ページを公開する前に、次の最終チェックリストを実行してください。
- インテントマッチ – アーキテクチャはユーザーの目的と一致していますか?
- URL – 簡潔で、キーワードが豊富で、ストップワードはありません。
- タイトルタグ – フロントローディング、60 文字未満、一意の値。
- メタディスクリプション – 105 ~ 160 文字、二次キーワード、行動喚起。
- 見出し階層 – H1 はタイトルと一致します。 H2/H3 は質問ベースで説明的なものです。
- 答えを導き出す – 各ヘッダーの後に 40 ~ 60 ワードの直接の回答。
- E-E-A-T 信号 – オリジナルのメディア、外部裏付けのある著者実体、逸話。
- 可読性 – Flesch 60+、文の長さ ≤ 17 ワード、Fog Index が 12 未満。
- セマンティックチャンキング – 抽出可能なモジュールに編成されたコンテンツ。
- 内部リンク – 1,000 単語あたり 2 ~ 5 個のコンテキスト リンク。 3 回のクリックですべての重要なページにアクセスできます。
- Core Web Vitals – LCP、CLS、INP の総合的な「良好」。 INP は 200ms 未満。
- 構造化データ(Schema) – @graph、Organization+Personal、sameAs、knowsAbout を含む JSON‑LD。
- 画像 – オリジナル、1200 ピクセル以上、WebP/AVIF、代替テキスト、スクロールせずに見える位置に配置。
- 製品スキーマのオーバーレイ – ビジュアル検索のリアルタイムの価格設定と利用可能性。
- 音声対応 – 会話上の質問に対する簡潔な回答。ローカル リスティングが最適化されました。
- ログレビュー – AI ボットが重要なページを確実に巡回するようにします。孤立したページはありません。
このガイドは理論的な記事ではありません。それは設計図です。
すべてのセクションには、最新のアルゴリズムの動作に対して検証された、現在動作しているものが反映されています。
2026 年のオンページ SEO は、精度、信頼性、技術的卓越性の分野です。
ここですべてを適用すれば、別のリソースは必要ありません。人間と機械の両方が信頼し、ランク付けし、そして最も重要なことに、引用されるサイトが完成します。